9 Things You Should Know About Data Agents in Microsoft Fabric
16th January 2026 . By Michael A, Colin N
In many organisations, data has never been more abundant, yet meaningful insights often feel frustratingly out of reach as senior leaders are surrounded by dashboards, reports, and metrics, but they still find themselves waiting on specialists to answer simple follow-up questions or explain why numbers have changed. This gap is becoming a real business constraint. As expectations for speed and agility increase, relying solely on static reports or over-stretched analytics teams no longer scales.
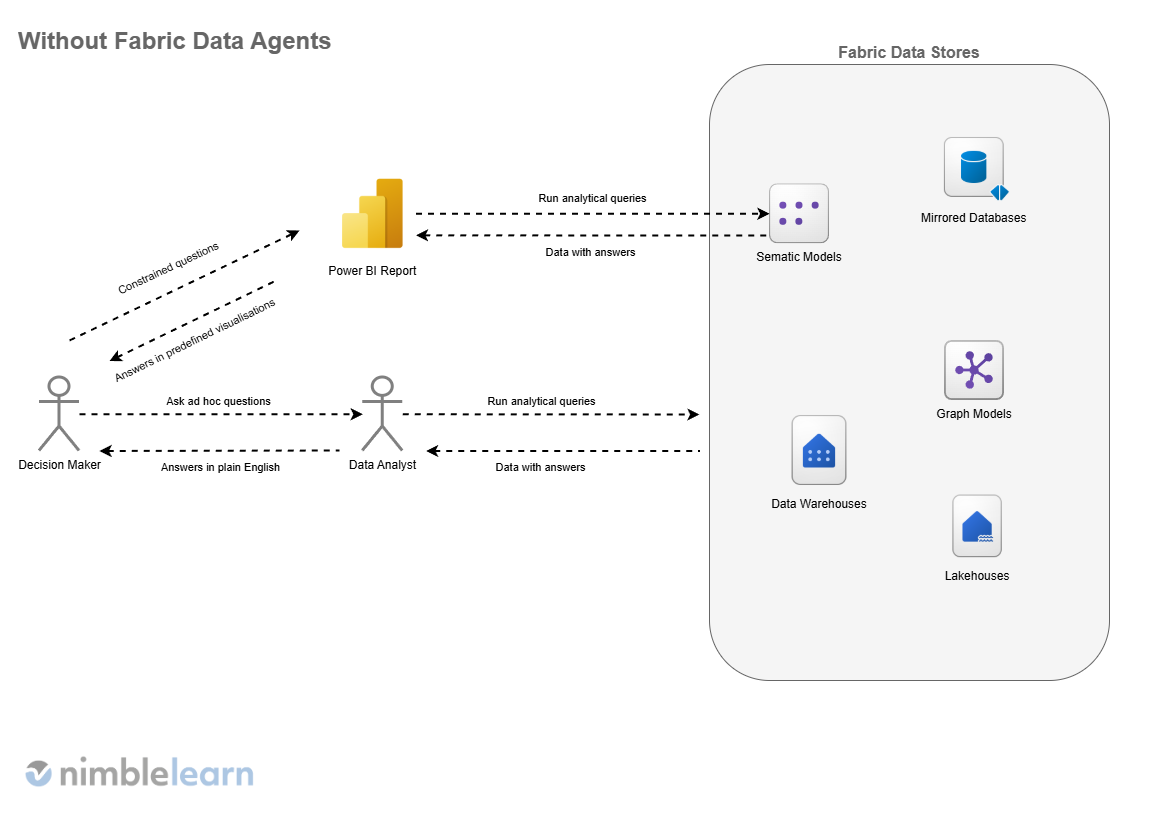
This is the problem that data agents in Microsoft Fabric are designed to address. Rather than replacing existing analytics or teams, they introduce a new way for people to interact with organisational data that is conversational, contextual, and closer to how leaders actually think and ask questions. Data agents sit between governed, structured data and decision-makers, turning complex datasets into something that feels accessible without stripping away rigour or governance.
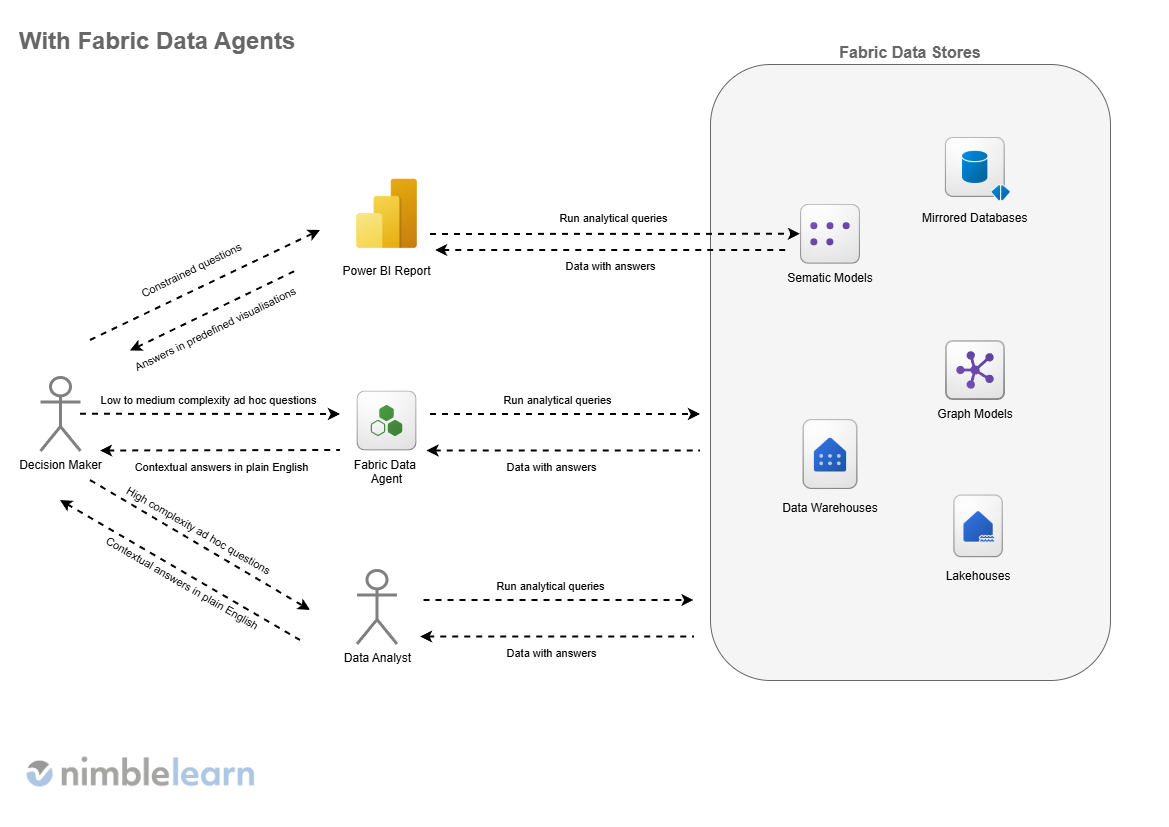
In this post, we’ll take a look at nine essential things every business leader should understand about data agents in Microsoft Fabric such as what they are, how they work, where they add real value, and just as importantly, where their limitations lie. The aim is not to dive into technical detail, but to provide a clear, practical perspective on why this capability matters and how to approach it strategically.
1. Build a Strong Foundation First
Before organisations get excited about what data agents can do, it’s worth spending time on the less glamorous question of what needs to be in place for them to succeed. Like any powerful capability, data agents amplify whatever environment they’re introduced into.
In a well-prepared organisation, they can unlock speed, clarity, and confidence. In a poorly prepared one, they often create confusion, risk, or disappointment. The difference is rarely the technology itself, but the foundation around it.
This foundation is not about model selection or technical architecture. It’s about intent, ownership, trust, and sustainability. A clear adoption framework helps ensure data agents are introduced as a strategic capability rather than a short-lived experiment.
1.1. AI Agent Adoption Framework
Planning ahead of agents
The most common early mistake is treating data agents as a playground for experimentation rather than a response to real business needs. Successful AI agent adoption in the context for Fabric data agents starts first by identifying specific questions leaders struggle to answer today such as:
- Why did performance drop last quarter?
- What's driving regional variance?
- Where are we exposed to risk?
When Fabric data agents are anchored to genuine decision-making pain points, their value becomes clear quickly. Conversely, vague “AI assistants” often fail to find a meaningful role. Starting with specific questions helps frame the agent’s purpose, define the domain knowledge, and determine the guardrails needed to answer these questions accurately and flexibly.
Governing and securing agents
For leaders to rely on agent-generated insights, they must trust both the answers and the boundaries around them. Governance is not an obstacle to adoption. Instead, it should be thought of as a prerequisite. Clear access controls, auditable interactions, and alignment with existing data security policies ensure that agents only surface information that users are entitled to see, as without this, confidence can fade fast, particularly in regulated or sensitive business environments.
Building agents with a focus
There is a strong temptation to aim for a single agent that “knows everything”. In practice, this usually leads to shallow answers and complex risk. Starting small with a narrowly defined domain, dataset, or use case allows teams to learn what works, refine instructions, and demonstrate value early, making these focused agents easier to improve and far more likely to gain user trust.
Managing agents across your organisation
Data agents should be treated as living systems because business priorities change over time, data evolves, and governance requirements tighten over time. Ongoing monitoring, evaluation, and refinement are essential. Organisations that plan for continuous management avoid stagnation and ensure agents remain aligned with real-world needs. Data agents rarely fail because the technology isn’t capable; they fail because planning, governance, and ownership weren’t taken seriously from the start.
1.2. Domain Focus Matters More Than Model Choice
One of the most common misconceptions about data agents is that their effectiveness depends primarily on how sophisticated the underlying model is, but this tends to be false and in reality, narrowly focused agents consistently outperform those designed to be general purpose.
An agent that understands a specific business domain, dataset, and set of decisions can deliver clearer, more reliable answers than one asked to cover everything, so without a defined domain and clear ownership, agents quickly become ambiguous in purpose and inconsistent in output.
Choosing where an agent should operate, and just as importantly, where it should not, is a leadership decision that reflects business priorities, accountability, and risk appetite, not technical preference.
1.3. Data Preparation Is Still the Bottleneck
Data agents do not remove the need for good data, but rather, they increase it since agents sit closer to decision-making, meaning they can amplify both the strengths and weaknesses of the data they rely on.
Clean, accurate, and well-structured data becomes significantly more valuable when paired with an agent, while poor-quality data leads to confident but misleading answers, making data quality a strategic multiplier rather than a background concern.
Leaders should set realistic expectations early: data agents will not tidy up fragmented, inconsistent, or poorly governed data estates. They work best when the fundamentals are already in place.
2. How Fabric Data Agents Are Consumed Across the Business
One of the strengths of data agents in Microsoft Fabric is that they are not tied to a single interface or audience, but instead are designed to be consumed across the organisation through multiple entry points, each tailored to different roles and ways of working.
This makes them versatile. It allows the same underlying intelligence to support everyone from executives, business users, and technical teams without fragmenting logic or duplicating effort, leading to a shared intelligence layer that adapts to how people already operate, rather than forcing the business to adopt yet another standalone tool.
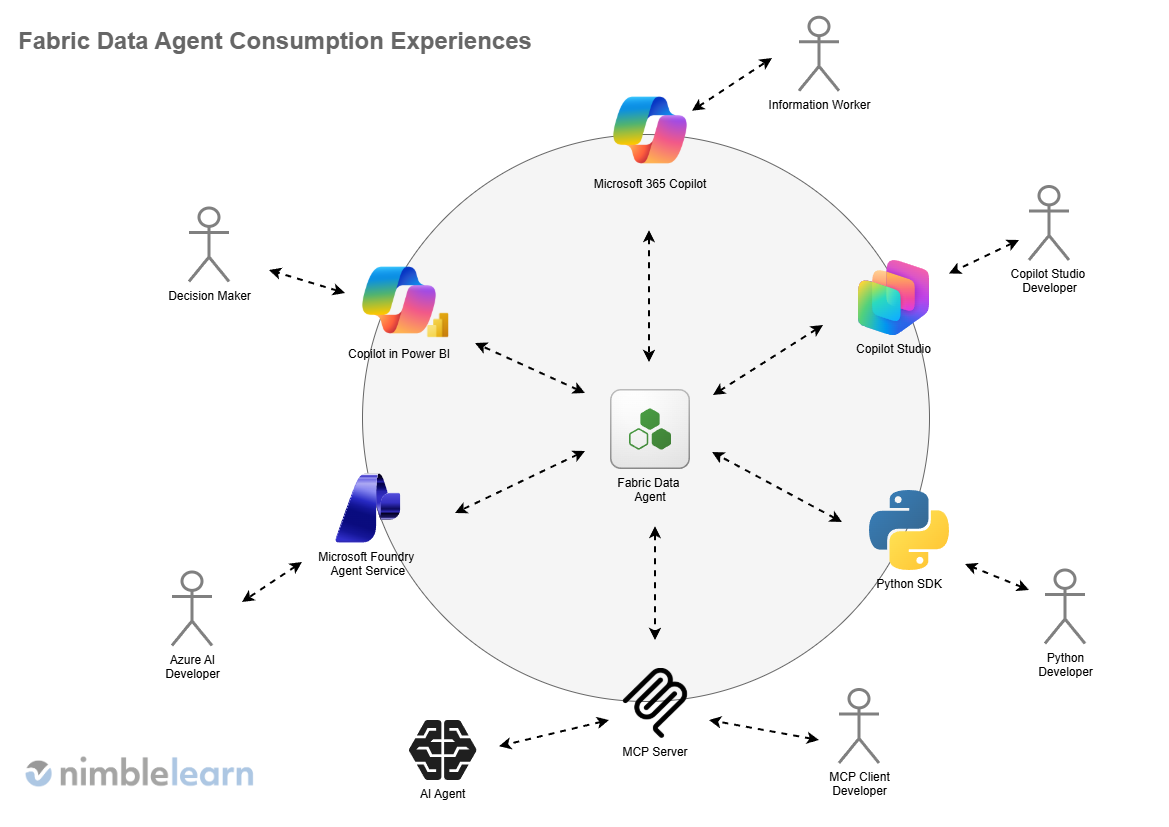
2.1. Microsoft Foundry Agent Service
Fabric data agents can be added to Microsoft Foundry Agents (previously called Azure AI Agents), enabling organisations to embed governed data intelligence directly into custom applications or internal platforms. This approach is particularly useful where insights need to be delivered inside line-of-business systems rather than through separate analytics tools. From a leadership perspective, this ensures data-driven intelligence shows up where decisions are actually made, not just where reports are viewed.
2.2. Copilot in Power BI
Copilot in Power BI is often the most intuitive entry point for data agents in analytics-led teams. It allows users to ask natural-language questions about their data and receive answers grounded in reports and semantic models in addition to Fabric data agents. Executives no longer need to interpret charts alone; they can explore why something is happening in the moment.
2.3. Microsoft 365 Copilot
By surfacing Fabric data agents inside Microsoft 365 Copilot, insights become available directly within familiar productivity tools, making it a powerful tool for senior leaders who spend most of their time in documents, presentations, and meetings rather than analytics platforms. The key advantage here is context, as data-driven answers appear alongside everyday work, reducing friction between insight and action.
2.4. Copilot Studio
Copilot Studio enables teams to design tailored conversational experiences backed by Fabric data agents. This allows organisations to shape how questions are asked, how answers are framed, and which data sources are used. Importantly, it reinforces the idea that executives don’t adopt platforms, but instead adopt experiences, making well-designed Copilots feel more purposeful rather than generic.
2.5. Python Client SDK
For more technical teams, the Python client SDK provides programmatic access to Fabric data agents, enabling full integration into automated workflows, advanced analytics, or custom tooling to ensure that agent intelligence can be reused consistently across technical solutions.
2.6. Model Context Protocol (MCP) Server
Fabric data agents can also be exposed via an MCP server, currently limited to Visual Studio Code, which supports advanced development and experimentation scenarios, particularly for teams building agent-centric solutions. It remains a specialist option, but an important one for extensibility. We expect this option to support more entry points in the near future.
3. Creation and Management Can Be Automated
As organisations move beyond a handful of experimental data agents, manual creation and management quickly become limiting factors, as creating agents one by one, configuring them individually, and maintaining them through ad-hoc processes does not scale in a large business. It introduces inconsistency, increases risk. It makes it difficult to understand which agents exist, who owns them, and what data they are allowed to access.
This is where automation becomes essential not as a technical convenience, but as an operational safeguard. Automated creation allows agents to be deployed consistently using predefined templates, standards, and guardrails. Just as importantly, automation supports proper lifecycle management. Agents should have clear owners, defined purposes, and an agreed process for updates, retirement, and replacement as business needs evolve, since without this, organisations accumulate “orphaned” agents that no one fully understands, yet they still continue to influence decisions.
Automation also strengthens governance. When agent creation, updates, and access changes are handled through controlled processes, leaders gain visibility and confidence. Auditability improves, policies are applied consistently, and risk is reduced. All without slowing the business down. This mirrors lessons learned from cloud adoption: managing agents manually is like managing cloud servers without DevOps. It might work at a small scale, but it quickly becomes fragile, opaque, and unsustainable. Automation turns agent management into a repeatable, trustworthy capability rather than a growing liability.
4. Agents Can Be Evaluated and Assessed Programmatically
For senior leaders, the idea of evaluating data agents may sound like a technical concern. In reality, it is a core risk management issue. As agents begin to influence decisions, recommendations, and narratives around performance, understanding how reliable they are becomes essential and trust should be earned through evidence, not assumed because the technology appears sophisticated.
Programmatic evaluation allows organisations to test agents against known scenarios, expected answers, and edge cases. This helps reduce hallucinations, which are confident but incorrect responses, before they reach decision-makers. More importantly, it shifts the focus from how intelligent an agent appears to how reliable it is over time. Consistency, accuracy, and predictable behaviour matter far more than occasional flashes of insight.
From a leadership perspective, evaluation provides assurance. It creates a feedback loop where issues are identified early, performance can be tracked, and improvements are measurable. When framed correctly, this is not about technical hygiene or model tuning, but more about controlling operational risk, protecting decision quality, and ensuring that data agents strengthen confidence rather than undermine it.
5. Azure OpenAI Under the Hood
Although Fabric data agents feel straightforward to use, they operate on top of enterprise controls that are very different from consumer AI tools. Under the hood, they use Azure OpenAI Assistants, meaning every interaction is processed through a managed, business-grade AI service rather than a public chatbot. This matters because it places data agents firmly inside the same governance, security, and compliance boundaries as the rest of your analytics platform.
Access is handled transparently through existing organisational identities (i.e. Microsoft Entra ID). Fabric tenant settings give administrators explicit control over who can use Copilot-powered features, whether data can be processed or stored outside a given geographic region, and whether Fabric data agents can be created and shared at all.
These are deliberate switches and not hidden defaults, which allows organisations to align their usage with regulatory, legal, and risk requirements. For scenarios involving Power BI semantic models, additional controls such as XMLA endpoints must be enabled to reinforce that agent capability is tightly coupled to governed data access.
For leaders, understanding this “under the hood” design is about trust and accountability. Consumer AI optimises for convenience and immediacy, while enterprise AI optimises for control, auditability, and predictable cost. Knowing that Fabric data agents sit on Azure OpenAI helps clarify why they can be safely embedded into decision-making processes, rather than remaining isolated experiments.
6. Data Agents Speak the Language of Your Data
One of the most overlooked strengths of Fabric data agents is their ability to work directly with the languages your Fabric data sources already understand. This is not a cosmetic feature, but actually fundamentally changes the depth and reliability of the answers agents can provide because instead of translating everything into a simplified layer, agents engage with data at its native level.
6.1. Why Query Languages Matter
Fabric data agents can reason over SQL, DAX, KQL, and GQL, each of which exists for a reason. These are referred to as Natural Language to SQL (NL2SQL), Natural Language to DAX (NL2DAX), Natural Language to KQL (NL2KQL), and Natural Language to GQL (NL2GQL), respectively. SQL supports structured transactional and analytical data in Fabric lakehouses, warehouses, and mirrored databases (support for Fabric SQL databases is coming soon). DAX powers analytical logic and measures in Power BI semantic models. KQL is optimised for high-volume log and telemetry analysis from data in Fabric KQL databases, while GQL enables graph-style queries across relationships in Fabric graph models.
Note that support for mirrored databases means Fabric data agents can indirectly query and reason over these additional SQL data sources using NL2SQL:
- Azure Cosmos DB
- Azure Database for PostgreSQL
- Azure Databricks catalog
- Azure SQL Database
- Azure SQL Managed Instance
- Oracle
- Snowflake
- SQL Server Database
Because agents understand these languages, they can answer questions that go far beyond what pre-built dashboards expose. Dashboards summarise what someone anticipated needing in advance. Agents allow leaders to ask follow-up questions, challenge assumptions, and explore causes in real time. It’s the difference between reading a prepared summary and being able to ask, “Why did this happen?” and “What if I look at it another way?” without starting a new reporting cycle.
6.2. Power BI and XMLA Considerations
Some capabilities, particularly around DAX querying, require specific configuration such as enabling XMLA endpoints in Power BI. This is not unusual; it reflects the fact that agents are interacting directly with analytical models rather than surface visuals. Leaders don’t need to understand the mechanics, but should expect that some setup is required to unlock deeper analytical interaction. This is a deliberate design choice, not a limitation.
6.3. Why This Is a Strategic Advantage
Crucially, agents adapt to your data estate rather than forcing your data into a new shape. This preserves existing investments while expanding how insight is accessed. It’s the ability to reason across the many different data sources in Fabric that is its true super power.
7. Sharing Agents Is Surprisingly Easy
Once created, Fabric data agents can be shared across teams with far less friction than traditional analytics assets, thus enabling the reuse of logic, instructions, and data access rules rather than recreating similar solutions in silos. When multiple teams rely on the same agent, answers become more consistent, reducing conflicting interpretations of the same data.
Just as importantly, easy sharing helps reduce “shadow analytics”, referring to unofficial spreadsheets, duplicated reports, and informal workarounds that thrive when access to insight is slow. Shared agents act as a common reference point, distributing knowledge in a controlled, governed way. From a leadership perspective, this is not just convenience; it is a knowledge-distribution strategy that improves alignment and confidence across the organisation.
8. Agent Instructions Are the Difference Between Useful and Useless
While models and data matter, instructions ultimately determine whether an agent is genuinely helpful or quietly dangerous. Agents do exactly what they are instructed to do and no more, no less, which makes instruction quality critical.
8.1. Why Instructions Matter
Poorly instructed agents often sound confident while producing misleading answers. This is particularly risky in executive contexts, where outputs may be acted upon quickly. As such, it’s important to give clear instructions to define scope, tone, and boundaries, reducing ambiguity and preventing agents from straying into speculation or inappropriate conclusions.
8.2. Types of Instructions That Matter Most
Three instruction types are especially important. Behavioural instructions define how the agent should respond, such as being cautious with uncertainty or highlighting assumptions. Example queries show what “good” questions and answers look like. Data source guidance clarifies which datasets take priority and how conflicts should be handled. Together, these encode organisational clarity directly into the system.
8.3. Best-Practice Mindset
The most successful teams treat agent instructions like policy documents that are deliberate, reviewed, and designed to endure rather than improvised.
-
Establish a shared business vocabulary: Agents interpret language literally. Undefined acronyms or ambiguous terms quickly lead to inconsistent answers. Clearly defining business terminology ensures the agent understands how the organisation uses language, not how a generic model might interpret it.
-
Prioritise clarity over volume: Overly verbose instructions often confuse rather than help. They dilute what actually matters. Well-scoped guidance keeps agents aligned to their purpose while reducing the risk of unintended behaviour.
-
Be explicit about the agent’s role: High-quality instructions explain what the agent is responsible for, what it should avoid, and how it should handle uncertainty. This gives the agent clarity.
-
Clarify how data sources should be interpreted: Agents need to know which data sources are authoritative, how to handle overlaps, and when to flag potential conflicts, so that it does not make silent assumptions that undermine trust.
-
Demonstrate expected behaviour through examples: Some expectations are easier to show than explain. Example queries demonstrate how to combine filters, measures, and logic in ways that abstract instructions alone cannot, anchoring behaviour in real-world usage.
9. Limitations and Strategic Considerations
It’s important to be clear about what Fabric data agents are and what they are not. They are not magic and data quality matters. They do not remove the need for good judgement, strong data foundations, or experienced people because agents can only work with the data, instructions, and access they are given, so when those inputs are weak, the outputs will reflect that reality, no matter how advanced the underlying technology appears.
Leaders should also be mindful that Fabric data agents are currently in public preview. This brings opportunity, but also responsibility. Features may evolve, behaviours may change, and organisations should expect a period of learning and adjustment. Treating agents as production-critical without appropriate oversight would be premature. A measured approach, focused on high-value but non-critical use cases, is often the most sensible starting point.
Observability is an area that Fabric data agents currently fall short. Although Fabric provides some governance related insights through Fabric’s OneLake Catalog, agent-level analytics, like what’s available for Copilot agents in Microsoft 365 Copilot, are absent. This is a gap that needs to be filled and is something we anticipate will be added close to or soon after the general availability milestone.
From a technical limitation standpoint, it’s important to note that Fabric data agents do not currently support unstructured data sources such as PDFs and Word documents. To workaround this limitation, you can (1) load the data into one of the supported data stores, or (2) pair Fabric data agents with one or more other agents (e.g. using Copilot Studio) as part of a multi-agent system. Learn more about the other technical limitations here.
Crucially, data agents are complementary to existing roles and assets, not replacements because they do not eliminate the need for data analysts, who remain essential for modelling, interpretation, and governance. Nor do they replace BI reports. These continue to provide trusted, repeatable views of performance. Instead, agents extend these capabilities by enabling exploration, explanation, and faster iteration.
Finally, there are regional and compliance considerations. In some scenarios, data sent to Azure OpenAI services may be processed or stored outside a Fabric capacity’s geographic region. This must be understood, assessed, and approved in line with organisational and regulatory requirements.
Conclusion: Data Agents as a Leadership Capability
Viewed narrowly, data agents can look like just another AI feature. Viewed strategically, they represent a shift in how organisations interact with information. They introduce a more conversational, responsive, and accessible layer between data and decision-making, one that complements existing analytics rather than competing with it.
The real competitive advantage does not come from having data agents, but from how they are deployed. Organisations that anchor agents to real business questions, govern them properly, and treat them as shared capabilities rather than isolated tools will move faster and with greater confidence. Those that chase novelty without structure are likely to be disappointed.
For leaders, this is ultimately about operating models, not technology. Data agents change who can ask questions, how quickly answers arrive, and how confidently insights are acted upon. Managed well, they reduce friction between data and decisions. The future of analytics isn’t more dashboards, but rather better conversations with data.
Next steps? Identify one high-friction decision area in your organisation and explore whether a domain-specific data agent could accelerate it.
