Exploring Data Factory Pipelines in Microsoft Fabric
18th November 2023 . By Tope O, Michael A
This article uses a simple example to explore what building a data pipeline is like with the Data Factory experience in Microsoft Fabric. It covers the following two main topics:
1. Creating a Microsoft Fabric Data Factory pipeline and adding activities to load a set of data files into a Fabric Data Warehouse
2. Comparing some features of Data Factory in Microsoft Fabric and Azure Data Factory
The 'Prescribing' dataset used for the examples is available to download for free from Open Data Blend.
It is a good practice to create metadata-driven pipelines in Microsoft Fabric if your skill level allows you to do this. That is the most scalable approach for data pipeline development and maintenance. This article focuses on using a small number of Fabric Data Factory pipeline features as opposed to implementing a production-grade solution so although it includes some metadata-driven practices, these appear in a basic form.
Creating a Data Factory Pipeline in Microsoft Fabric
You need a Microsoft Fabric Workspace before you can create a Data Factory in Microsoft Fabric. The most frictionless way to do this is to start a free trial, which lasts for 60 days at the time of writing.
The steps mentioned in this article start from the point of already having a Microsoft Fabric workspace.
From the Fabric Home page, we click the 'Create' button, which can be found on the left-hand panel of the home page.
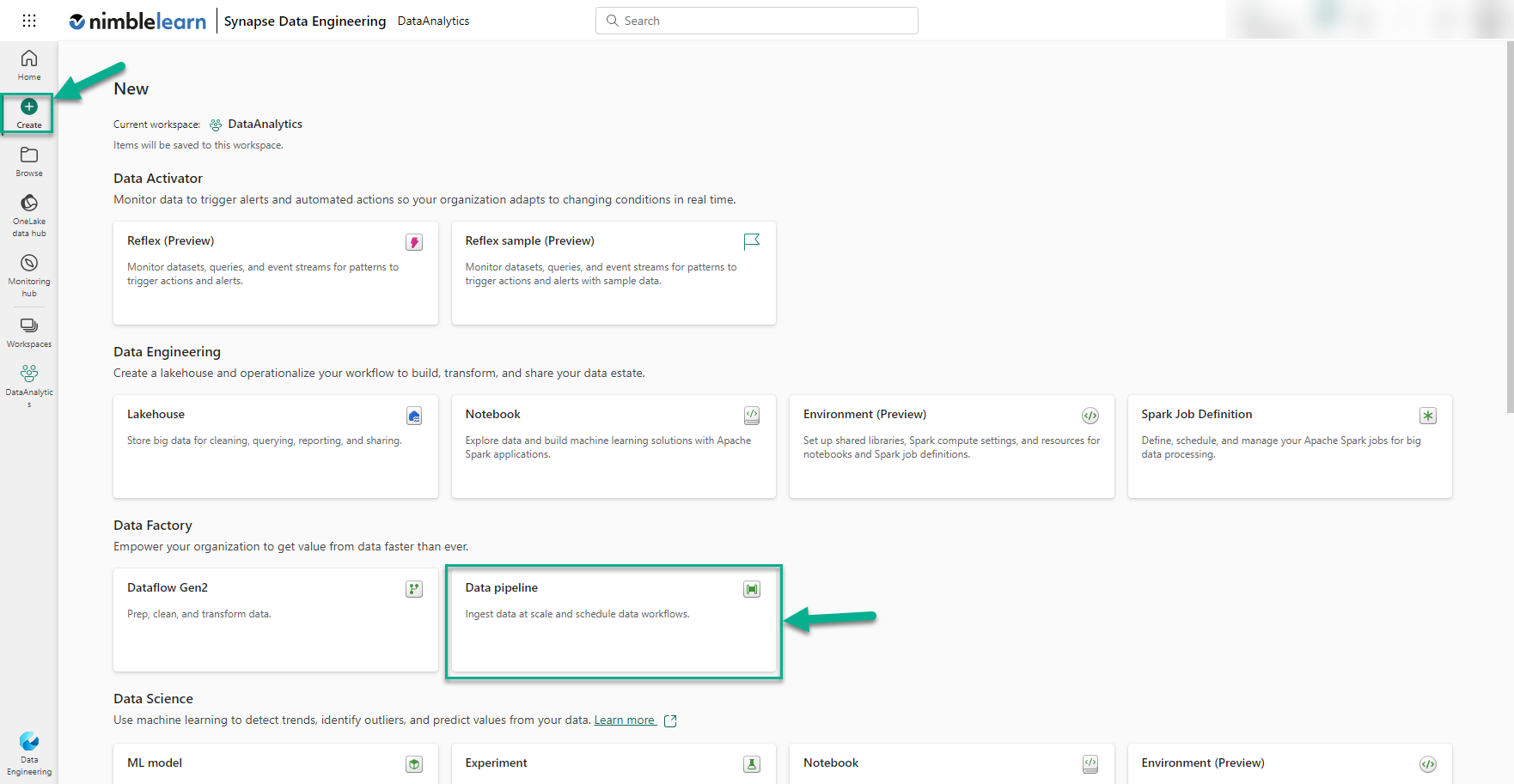
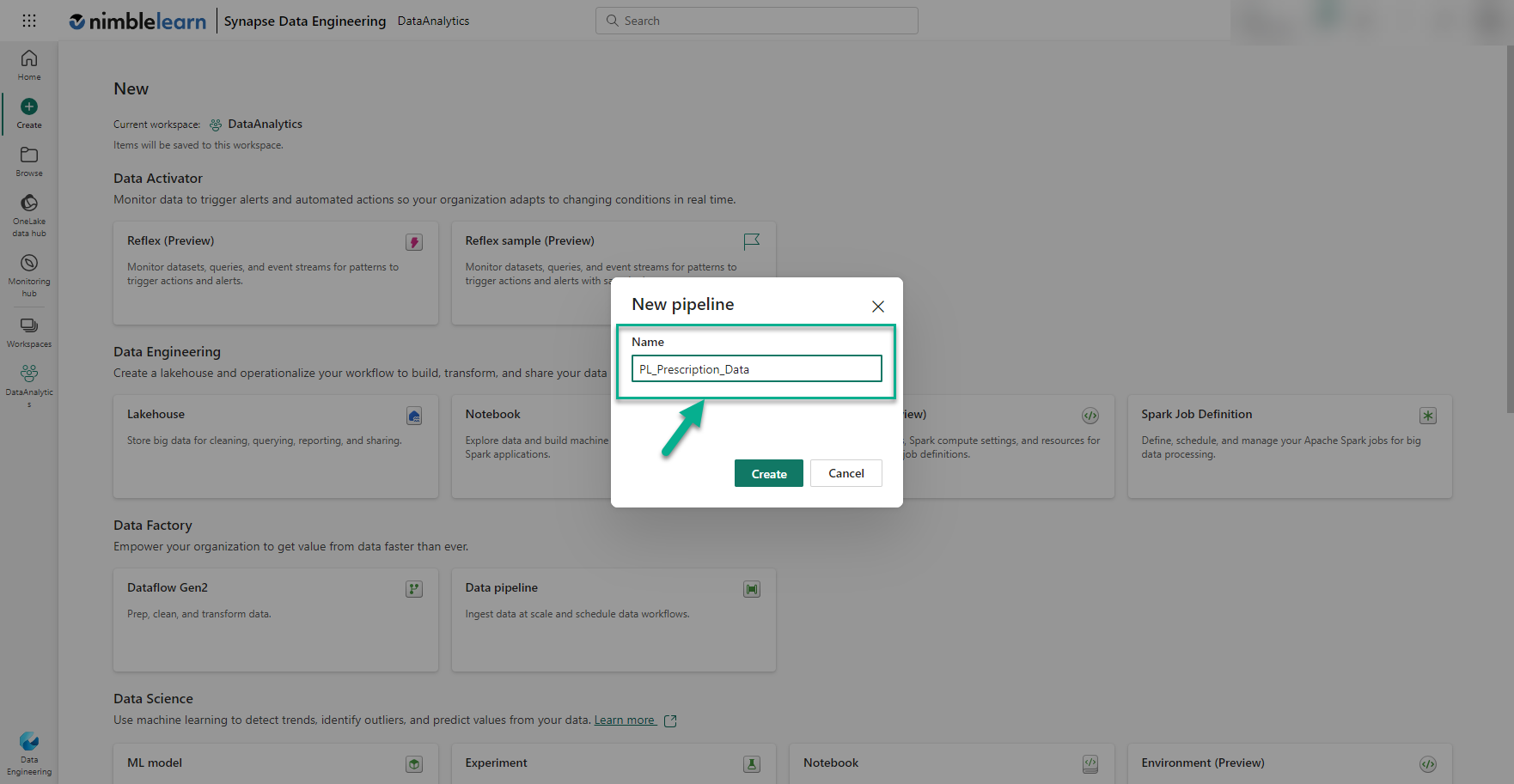
This presents a page showing all the different Microsoft Fabric services that can be created within the workspace. We click the 'Data pipeline' tile and enter the name of the new pipeline into the pop-up form that appears. It is a good practice to use meaningful names so, in this example, we name the pipeline 'PL_Prescription_Data'. Here we are using the 'PL' prefix to indicate that this is a data pipeline. There are no hard rules on what prefixes and naming conventions to follow but this is something you should decide on before creating your Fabric items.
Whilst on the 'Create' page, we followed similar steps to create a Fabric Data Warehouse called 'DW_ODB' and a Fabric Lakehouse called 'LH_ODB'. These are used for the data source and data destination, respectively, in later steps.
Using Microsoft Fabric Data Factory to Build a Data Pipeline
Ahead of starting to build the data pipeline, we downloaded some prescribing data files and stored them in an Azure Data Lake Storage (ADLS) Gen2 account. It is worth highlighting that, at the time of writing, there is no Self-hosted Integration Runtime for the data pipelines the Fabric Data Factory, which means the pipelines cannot connect directly to on-premises data sources yet. However, this gap will be plugged through on-premises data gateway support which is planned for Q1 2024 at the time of writing. The Microsoft-suggested workaround for this limitation, in the meantime, is to use a Dataflows Gen2 activity to load on-premises data into a cloud destination.
If you do not have access to an ADLS Gen2 account, you can store the data files in a Fabric Lakehouse, and use that as the data source instead. We created a lakehouse in one of our earlier steps called 'LH_ODB' to illustrate how this can be used as a data source instead of ADLS Gen2. In either scenario, the data warehouse we created called 'DW_ODB' is used as the destination for the data pipeline. Now is a good point to highlight that we are only using ADLS Gen2 or a Fabric Lakehouse as data sources in the data pipeline to illustrate how the pipelines work. Alternative and potentially simpler methods for using data in a Fabric Data Warehouse is through OneLake Shortcuts or the COPY statement.
Note: You can use a Python library called opendatablend to load an Open Data Blend dataset into ADLS Gen2 or a Fabric Lakehouse by calling it from a Fabric Notebook.
Data Engineering with Microsoft Fabric
With the data files available in an ADLS Gen2 account, we use the Get Metadata activity within the data pipeline (i.e. PL_Prescription_Data) to obtain the list of all the data files to be loaded into the Fabric Data Warehouse (i.e. DW_ODB). You can see how we configure the Get Metadata activity below.
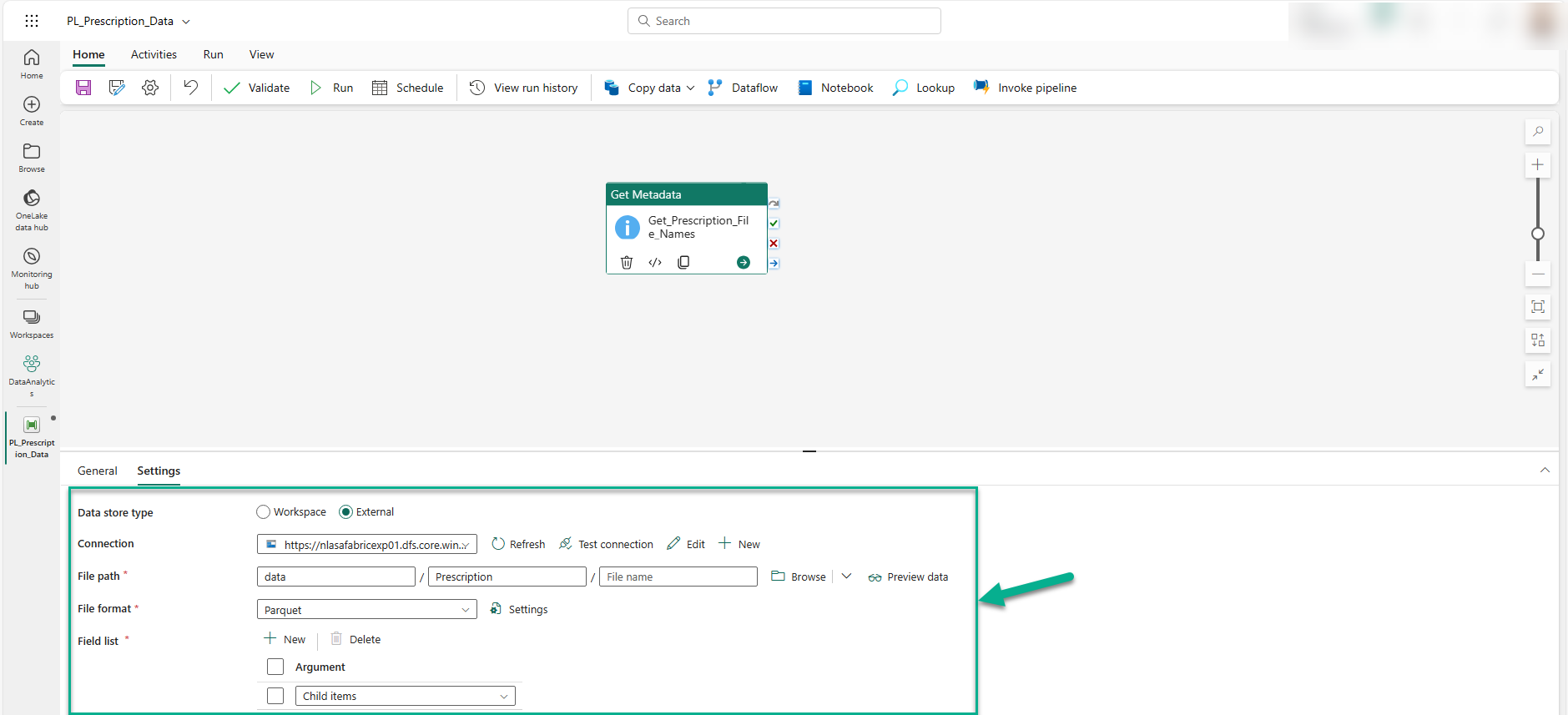
In the image above, 'External' is selected for the 'Data store type' property. ADLS Gen2 was chosen as the 'Connection' property and the ADLS Gen2 account is selected. Once the connection is established, we set the 'File path' property. The 'ChildItems' option is chosen from the drop-down within 'Field list' property section, allowing us to obtain metadata about the collection of files stored in the 'data/Prescription/' file path after connecting to the ADLS Gen2.
The importance of the Get Metadata activity above is that it helps us retrieve the names of all the files that need to be loaded, and presents them as a list through the output property of the activity. It is vital to already have the correct file names in your ADLS Gen2 account at this point as these are used at a later stage to determine the name of the destination tables in the Fabric Data Warehouse. In our example, the names of the data files were made more user-friendly ahead of later steps. When we run the 'Get_Prescription_File_Names' Get Metadata activity, the output shows the name of each file in the folder, which you can see in the following image.
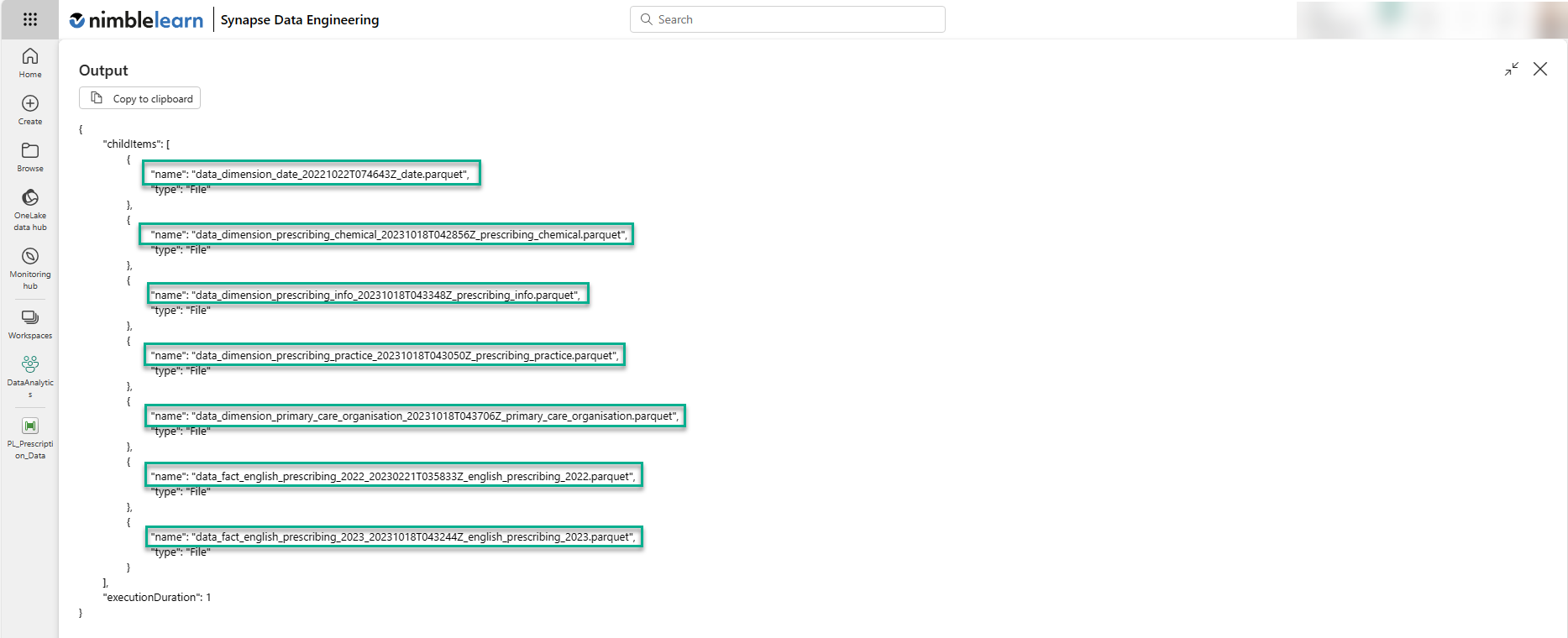
In the image above, the name attribute is significant because it is passed on to the item configuration setting that we create next.
To configure the Get Metadata activity for a Fabric Lakehouse data source, we do things slightly differently as can be seen below.
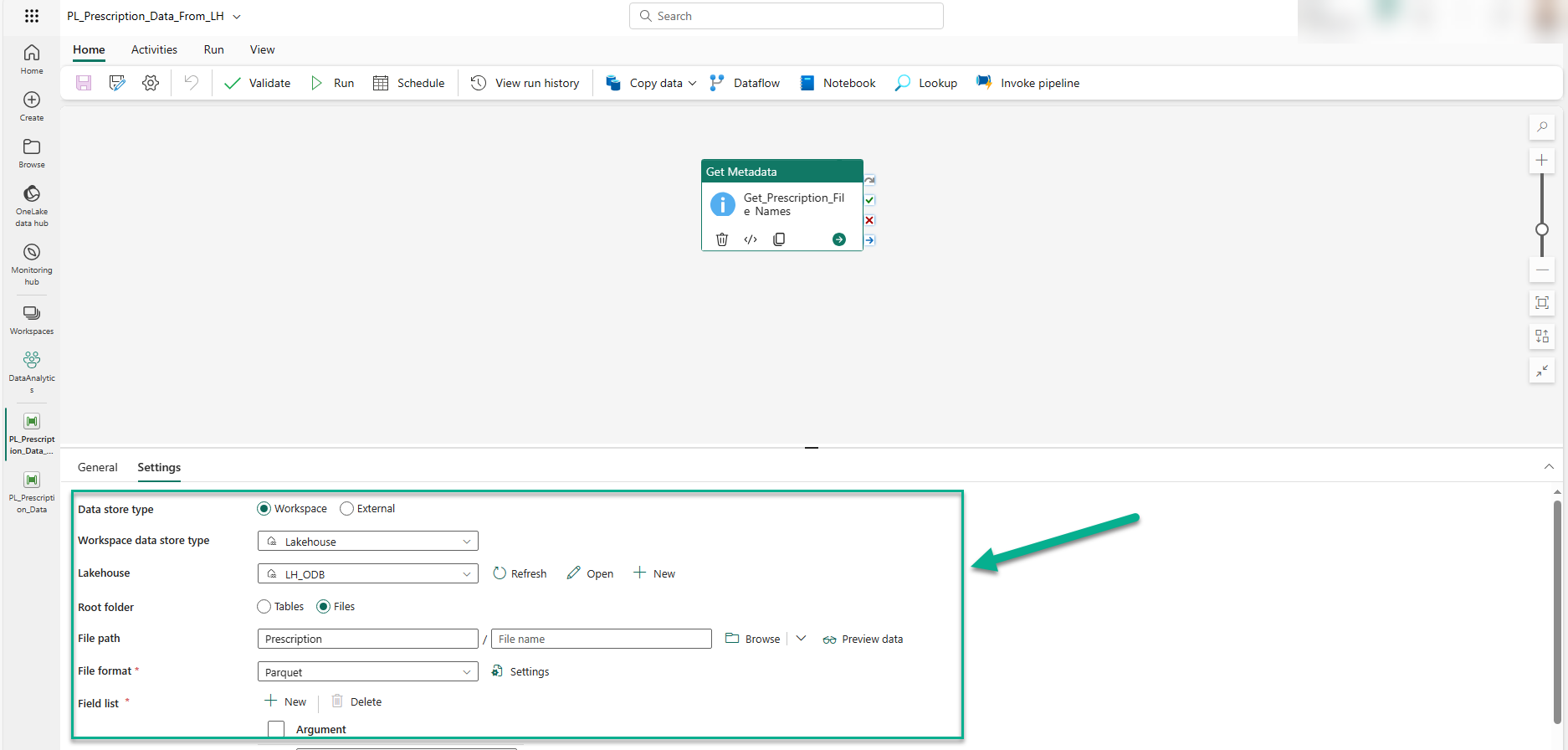
The main differences are that 'Workspace' is selected for the 'Data store type' property, and our Lakehouse service (i.e. LH_ODB) is chosen as for the 'Lakehouse' property.
Now that the pipeline knows the files need to be loaded, we use the ForEach activity to help us load all the files in our ADLS folder into our Data Warehouse. We will walk through the configuration steps used in the ForEach activity, and the Copy Data activity that it runs for each data file passed on from the Get Metadata activity.
The first thing we configure after adding the ForEach activity to the canvas, and connecting it to the Get Metadata activity, is the 'Sequential' property. This setting tells the ForEach activity whether to iterate over the items it handles in parallel. In this case, we tick the 'Sequential' property because this is a simple data pipeline and parallel executions require careful consideration due to issues such as race conditions (e.g. a conflict due to attempting to load multiple files into the same table at the same time). If we did leave this setting unticked, a 'Batch count' property would be visible and this controls the maximum number of items that can be processed in parallel (e.g. up to four at a time).
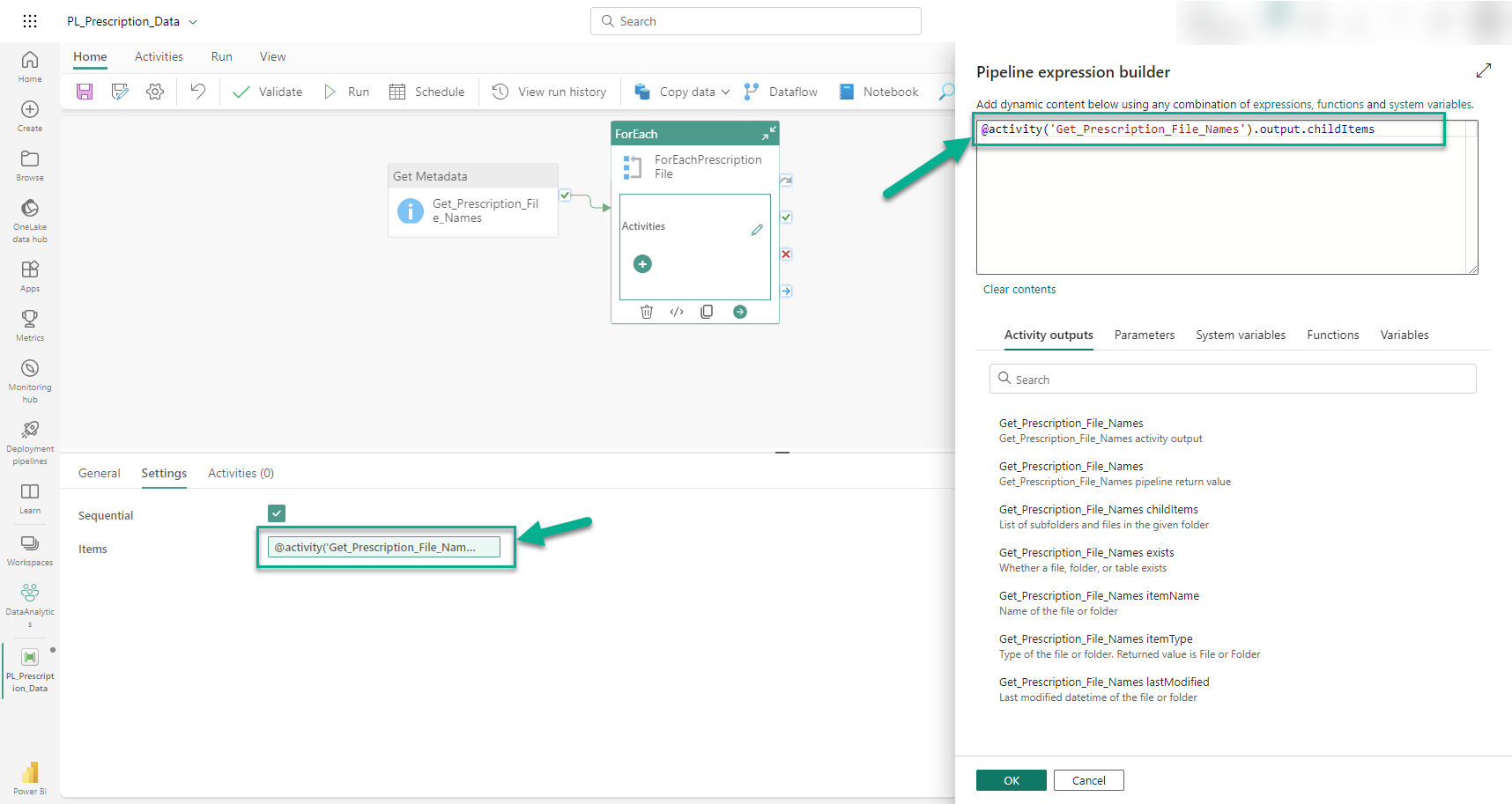
In the image above, we use create the pipeline expression for the 'items' property using 'Pipeline expression builder'. In this example, the expression tells the ForEach activity to get the 'childItems' property from the output of the Get Metadata activity (i.e. Get_Prescription_File_Names).
The expression we use is:
@activity('Get_Prescription_File_Names').output.childItems
We add a Copy Data activity by clicking the plus (+) icon inside the ForEach Activity. This is what the ForEach activity will execute to load each data file into the Fabric Data Warehouse.
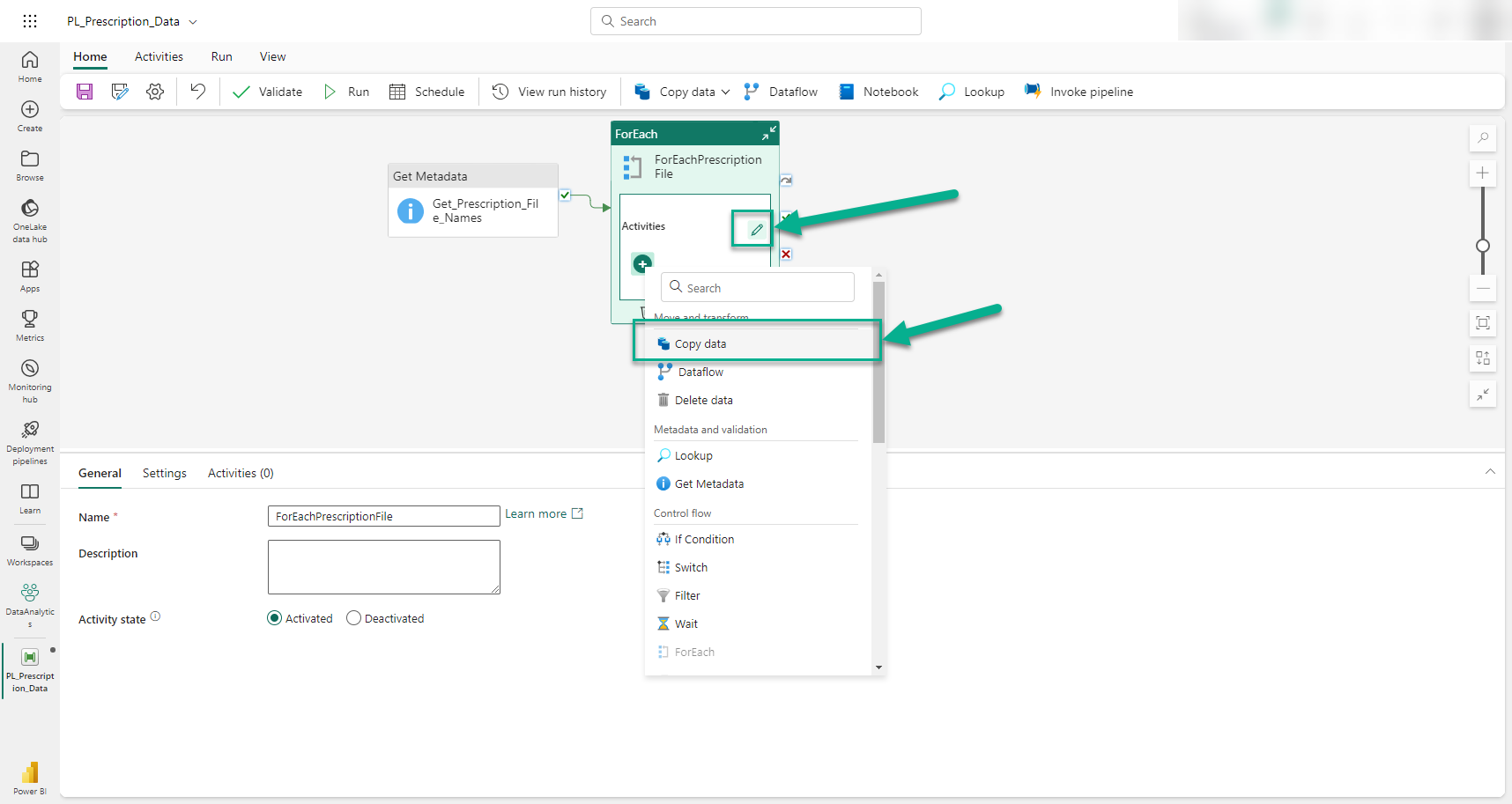
Once the Copy Data activity is added, we give it a meaningful name (i.e. 'Copy_Prescription_Files') and move on to configuring its Source and Destination properties. We start with the Source connection properties, as shown in the image below.
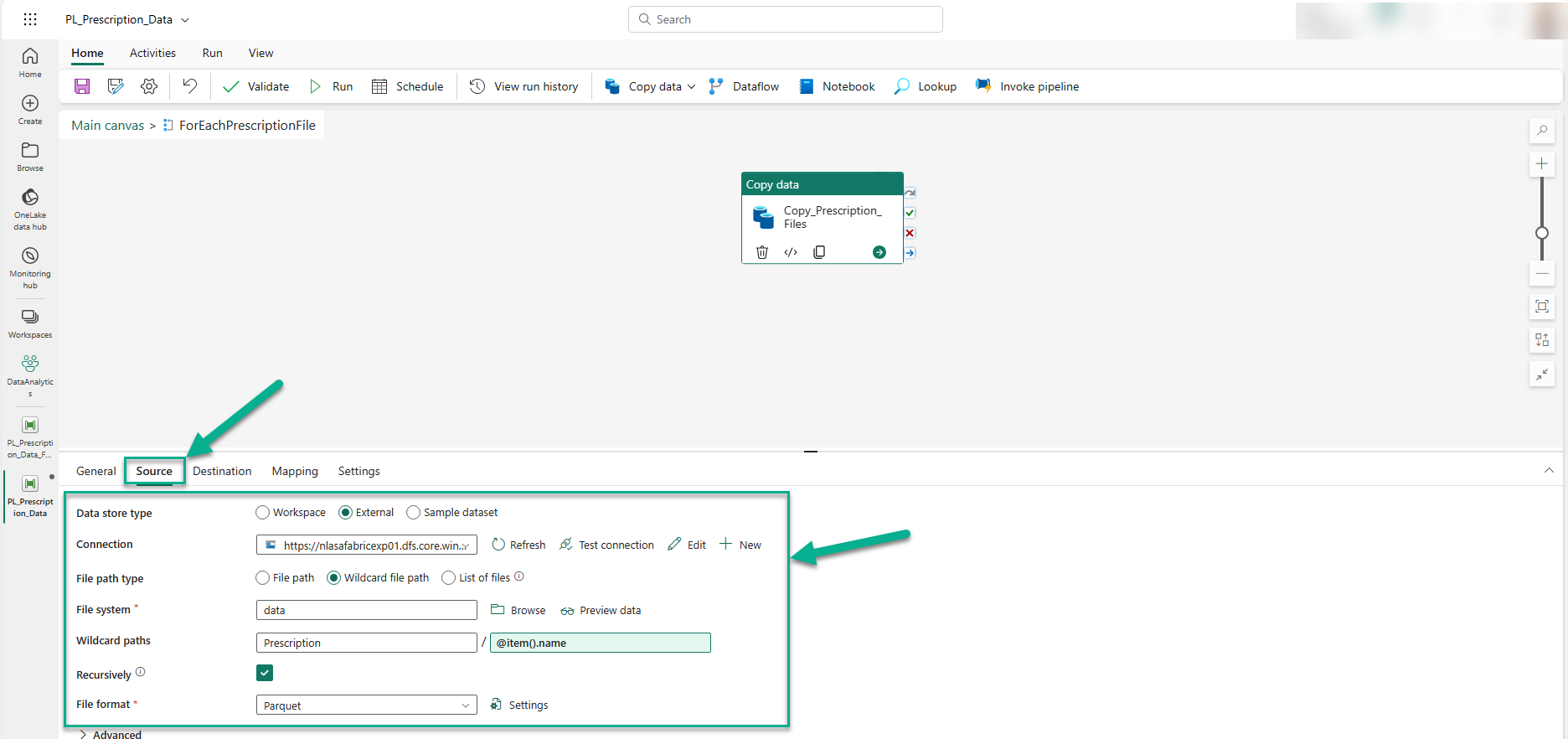
You can see that the 'Data store type' property is set to 'External', similar to the Get Metadata activity, the ADLS Gen2 account is used for the 'Connection' property. The 'File path type' is set to 'Wildcard paths', with '@item().name' representing the name of each file that will be processed when looping through the list of data files. Finally, the 'File format' property is set to 'Parquet', as that is the format of all the data files we are reading from the ADLS Gen2 location.
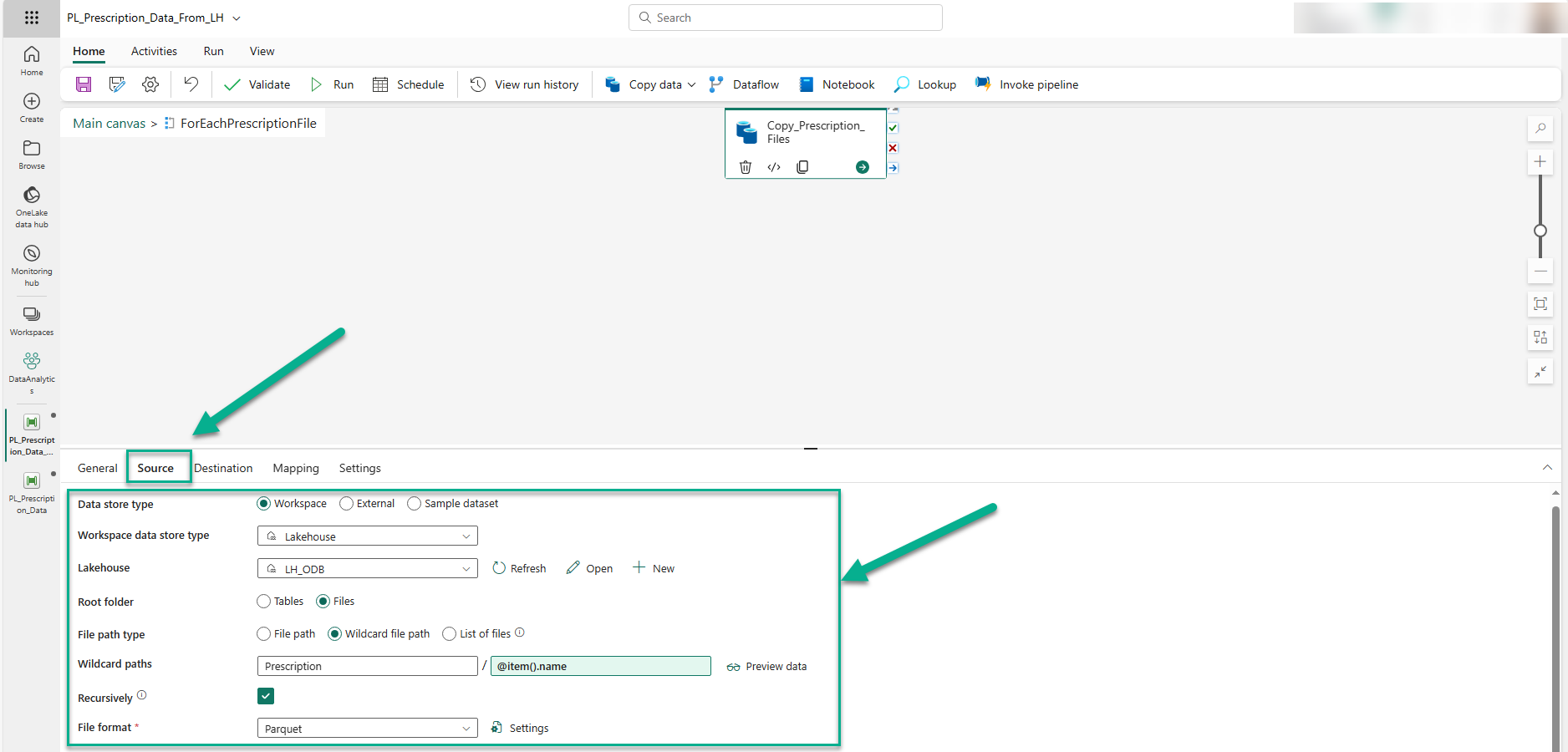
The settings described here largely remain the same if a Fabric Lakehouse is used as the data source instead of an ADLS Gen2 location. However, the 'Data store type' would be 'Workspace', and the 'Lakehouse' would be set to our Fabric lakehouse (i.e. 'LH_ODB') as shown in the image below.
Next, we switch to the Destination connection properties and set the 'Data store type' to 'Workspace', 'Workspace data store type' to 'Data Warehouse', and 'Data Warehouse' to 'DW_ODB' since our destination is a Fabric Data Warehouse. In our example, we want the tables to automatically be created so we set the 'Table option' to 'Auto create table' and derive the table names from the data files names by setting the 'Table' properties to 'landing', which will become the schema name, and '@landing.item().name' which is a placeholder for each data file name retrieved from the Get Metadata activity. For clarification, the 'Table' properties are the two-part object name (e.g. 'landing.table_name) to be used when creating a table and loading data into it.
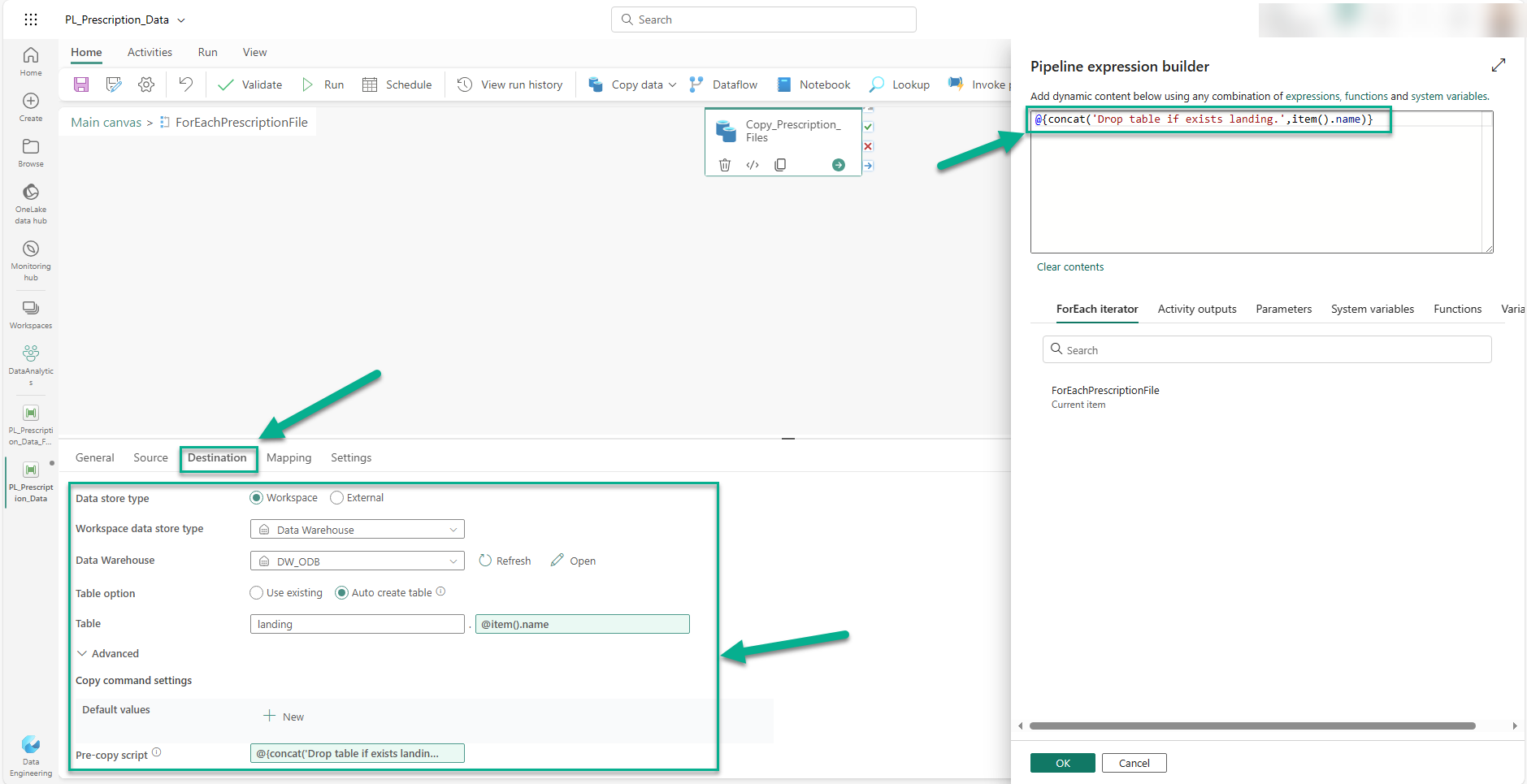
Finally, as this is a pipeline that could be run multiple times, it is essential to use a pre-copy script so that on each run of the pipeline it drops the existing tables before attempting to create tables of the same name. In this simple example, we recreate the tables by dropping them first using the following expression in the 'Pre-copy script' property:
@{concat('Drop table if exists landing.',item().name)}
After configuring the destination, we can save and run the pipeline, as we do not need to change any settings under the 'Mapping' or 'Settings' tabs of the Copy Data activity. The image below shows the DW_ODB Fabric Data Warehouse after successfully running the pipeline.
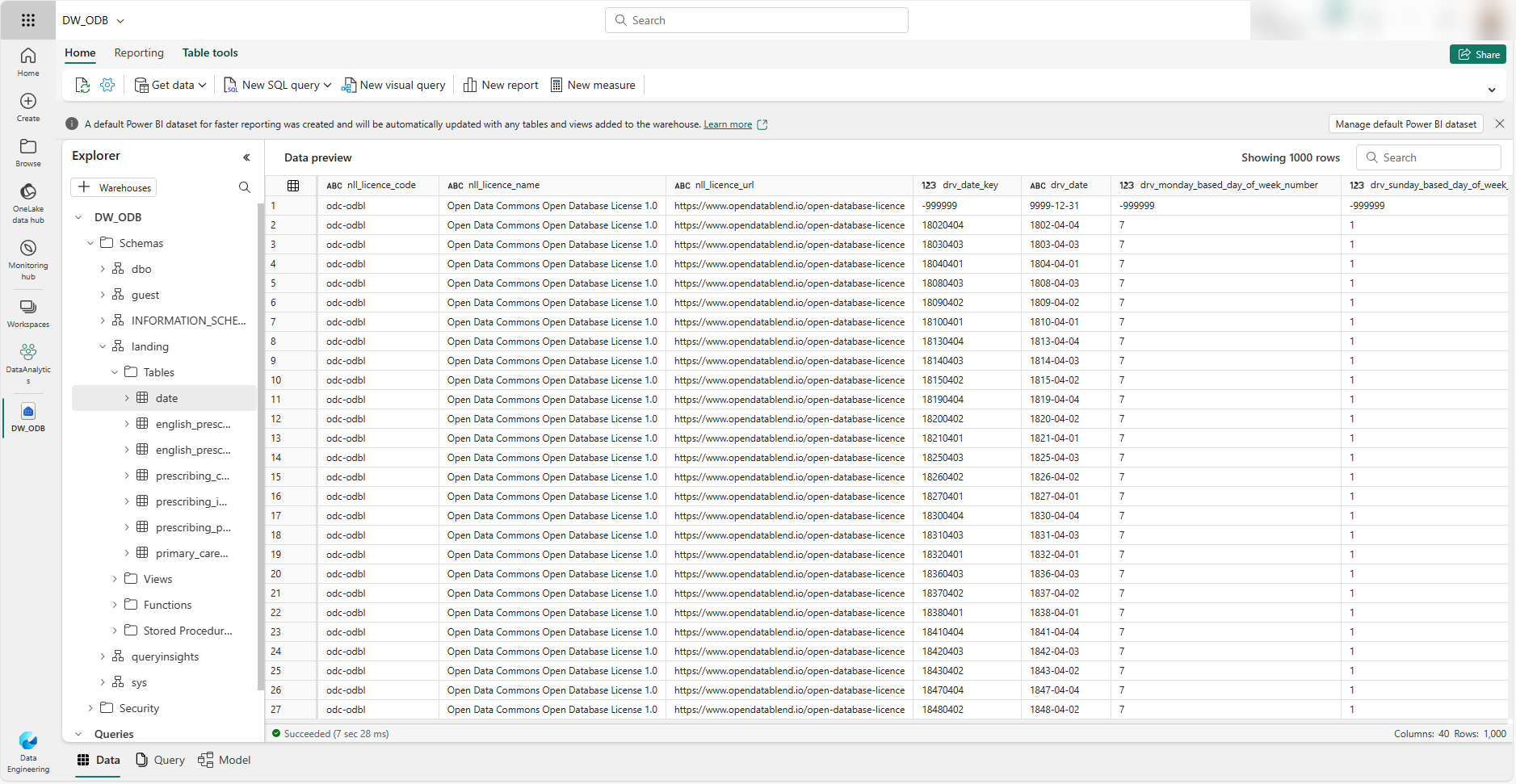
Now that the data is loaded into the Fabric Data Warehouse, other transformations can be performed using a combination of pipeline activities such as notebooks, stored procedures, and dataflows. You can also query the data using the visual query editor or, if you know T-SQL, from the SQL query editor.
There are several methods for getting data into Microsoft Fabric and extracting value from it. We will explore some of these in future articles.
Comparisons with Azure Data Factory
For readers familiar with using Azure Data Factory for performing ETL/ELT activities, you will notice that the Fabric Data Factory interface feels familiar, and the majority of what has been done throughout this article can be achieved the same way as in Azure Data Factory. However, there are a few differences that you will notice immediately. For example, rather than having your pipeline activities listed on the left-hand side of the user interface , pipeline activities are listed along the top of the Data Factory in Microsoft Fabric. You will also find that some of the activities available in Azure Data Factory are not yet present in the Fabric Data Factory. These activities include, but are not limited to Hive, MapReduce, and Pig.
Azure Data Factory users familiar with having datasets, pipelines, data flows and Power Query displayed on the left-hand side of the Azure Data Factory Studio will also notice that these are not shown the same way in the Fabric Data Factory. Users wishing to use the Power Query activity can access a superior iteration of this experience in the form of Dataflows Gen2. It is essential to note that the Microsoft Fabric team are rapidly plugging the feature gaps and going beyond these to add new capabilities that are enabled by Microsoft Fabric's holistic approach to data analytics. Furthermore, there are already new activities that users of the Fabric Data Factory can use today in their pipelines including the Office 365 Outlook activity and the Teams activity. You can see the announcement for these additions here.
Conclusion
This article explored how to use three Microsoft Fabric services (Data Factory, Lakehouse, and Data Warehouse) for extracting and loading data into a data warehouse from where further transformations can then take place or from where the data warehouse can be used as a data source for a Power BI report. Furthermore, comparisons were made between Azure Data Factory and the Data Factory in Microsoft Fabric to help users who might be more familiar with Azure Data Factory understand some differences between the two. In summary, it is easy to argue that using these services within Microsoft Fabric is much simpler than provisioning the different services in Azure, as users do not have to worry about abstract concepts such as resource groups and subscriptions. Moreover, the ease of having all the Fabric services at your fingertips will enable new and exciting possibilities that are only made possible with a complete analytics platform like Fabric.
Follow Us and Stay Up to Date
Get notified when we post something new by following us on LinkedIn and X.
